
当AI学会欺骗,我们该如何应对?
当AI学会欺骗,我们该如何应对?前沿模型越来越多地被训练和部署为自主智能体。一个安全担忧是,AI智能体可能会隐秘地追求与人类目标不一致的目标,隐藏其真实能力和目的——这也被称为AI欺骗或谋划行为(AI deception or scheming)。
来自主题: AI资讯
11758 点击 2025-07-24 11:34
 搜索
搜索
前沿模型越来越多地被训练和部署为自主智能体。一个安全担忧是,AI智能体可能会隐秘地追求与人类目标不一致的目标,隐藏其真实能力和目的——这也被称为AI欺骗或谋划行为(AI deception or scheming)。

AI 解放生产力的奇点,可能就在 2025 年。「2025 年会成为智能体爆发的一年」这一判断基本已经成为了行业内的共识。这一点从第三方机构 aicpb AI 产品榜的变化就可以看出。

AI 正在扩展人类认知。 人类历史始于书写。铭文是最早的书写形式之一,提供了关于古代文明思想、语言和历史的直接洞见。
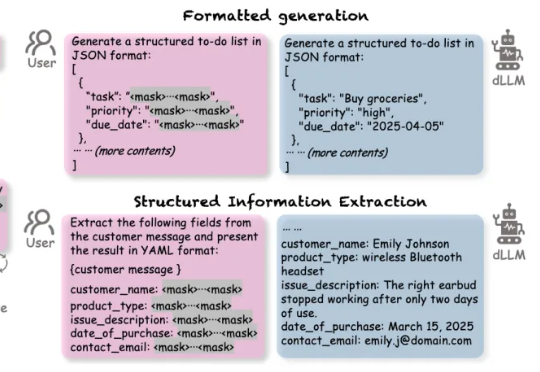
扩散语言模型(Diffusion-based LLMs,简称 dLLMs)以其并行解码、双向上下文建模、灵活插入masked token进行解码的特性,成为一个重要的发展方向。
昨天,《华尔街日报》报道称,OpenAI 和软银在推迟了 6 个月的星际之门(Stargate)项目上出现了争执,并大幅缩减了近期计划。

自 ChatGPT 引爆公众认知以来,AI 开始渗透进写作、编程、设计等多个应用场景,推动人类进入“智能体(Agent)”时代。曾经遥不可及的自动化交互,如今正在成为现实。在这背后,一场关于基础设施的重构也悄然展开——从模型能力到部署体验,谁能打通智能 Agent 的“最后一公里”,谁就掌握了这场范式变革的主动权。

3D生成又补齐了一块重要拼图——物理属性! 南洋理工大学-商汤联合研究中心S-Lab,及上海人工智能实验室合作提出了PhysXNet,号称首个系统性标注的物理基础3D数据集。

请你让我享受发现美、创造美的过程。

7 月 22 日,华盛顿 DC。 美联储举办的“大型银行资本框架综合评估”年会,本是监管部门闭门核算风险权重的场合,却因为一位科技掌门人的一句话突然炸锅:

承认吧,AI 已经彻底卷进了我们的生活。